Project 2: Sierra Costera Site Evaluation - Part 1
Project 2: Sierra Costera Site Evaluation - Part 1♦ Overview♦ Scenario1. Create the project workspace template2. Add and prepare provided data3. Surface analysis4. Hydrologic analysis 4.1 Deriving a stream network from a DEM4.2 Calculating upstream areas5. Terrain Analyses5.1 Topographic Convergence Index (TCI)5.2 Topographic Position Index (TPI)5.3 Slope PositionManual calculation of Slope Position from TPIUsing the provided Slope Position script tool5.4 Landforms♦ Summary
♦ Overview
Digital Elevation Model (DEM) data are widely available and can be used to derive a variety of ecologically meaningful spatial layers. Here we explore how to use DEM data to derive both hydrologic features (streams, watershed boundaries) and terrain-based indices that are often useful in identifying ecologically distinct areas within a landscape.
Use the scenario below to familiarize yourself with how these metrics are calculated in ArcGIS. I've provided some tools that allow you to overcome some of the more tedious components of certain analyses; feel free to keep copies of these tools and use them beyond this class. However, it's essential that you have at least a conceptual idea how these tools work, so be sure to ask if you need further explanation about any process used in this exercise.
The data for this lab are found in the Project2Data.zip file.
♦ Scenario
WWF-Mexico is preparing for a workshop reviewing conservation priorities in the Sierra Costera de Oaxaca -- the coastal mountains on the southern coast of Oaxaca, Mexico. At present, data for the region are limited and they only have a 3 arc-second (90m) DEM for the entire study area along with a 1/2 arc-second DEM (15m) for a selected portion of the area. Still, they need you to help with two pressing requests.
- First, a number of workshop participants will be bringing species observation data with them (GPS coordinates of where they searched for individuals of various important species). Many are interested in determining whether distance from stream is a good predictor for species presences -knowledge that will be important in defining conservation priorities within the region. In order to calculate this, however, they need a stream map for remote locations where they have only DEM data. Your first task then is to create this stream map for WWF.
- The second request involves determining the drainage area for five stream gauge locations. Each gauge site is a known location of a rare and endangered amphibian, and WWF is interested in protecting at least one of these drainage areas. Which drainage area they chose depends on several factors and will be a focus of the upcoming workshop, but they first need you to determine some general topographic characteristics of each drainage area. So, your second task is to generate maps of a set of topographic indicators for these drainage areas as well as tabulate a set of summary statistics to facilitate comparison of these sites.
Specific instructions regarding the deliverables will be provided in a separate document, but you are to begin your analysis using the guidelines below.
Let's get started!
1. Create the project workspace template
As usual, the first step in most any analysis is to create a workspace for your project. Start this project as we've learned previously by creating a project folder with the usual subfolders within it ("Data", "Docs", "Scratch"). This time, however, also create a "Scripts" folder as we'll be using some Python scripts in this exercise. Create an ArcGIS Pro project named SierraCostera, in this folder and finally set the workspace environment variables.
2. Add and prepare provided data
Unzip the Project2Data.zip file to your V: drive. The resulting folder contains a geodatabase, two toolboxes, some Python scripts, a set of LYR files, and "TarDEM" -- a folder containing executable files developed by David Tarboton at Utah State that provide some hydrologic analyses that improve upon ArcGIS's raster tools. You need to sort through these files and place them in the correct location in your workspace.
The SierraCostera_UTM14.gdb geodatabase contains the datasets listed below. Each dataset is projected to the UTM Zone 14 (NAD 83) coordinate system.
DEM_90m-- A 90m DEM provided by Mexico's National Institute of Statistics and Geography (INEGI). The original ".bil" file was subset to the Sierra Costera study region and reprojected to the UTM 14 (NAD 83) coordinate system using bilinear resampling, keeping the original 90m cell size.DEM_15mf-- A 15m DEM also provided by INEGI, converted and reprojected to the UTM. This dataset, however, was subset to a smaller region. It has also been "filled" (discussed later in this exercise).GaugeSites-- A point feature class representing the 5 stream gauge locations for which upslope analysis will be conducted.
→ Prepare the datasets for analysis:
- Unzip the SierraCostera_UTM14.gdb geodatabase into your project's Data folder.
- Add all the datasets to a new (or existing) map in your ArcGIS project and symbolize them, if desired.
The files with a
.pyextension are Python scripts. We don't go into writing Python scripts in this course, but we will use them. These Python scripts are linked to tools in the ENV761_TerrainTools.tbx. For them to work, they need to be stored in the Scripts folder.- Move the Python script files to the Scripts folder.
As mentioned above, the TarDEM folder contains executable files that can perform spatial analyses on ASCII format rasters. These files are used in some of the Python scripts.
- Move the TarDEM folder into your Scripts folder.
Lastly, the folder called LayerTemplates includes some ArcMap LYR files. The
Acervo de informacion geografica INEGI (Mapa Digital de Mexico) on gaia.inegi.org.mx.wmsfile links to a web mapping service containing several base layers. The other LYR files do not point to specific datasets but rather contain symbology which can be applied to layers created in this lab.- Move the LayerTemplates folder into your Data folder.
→ When these steps are complete you are ready to proceed with the analysis and your workspace should resemble this:

3. Surface analysis
We'll start simply by deriving a few datasets from our DEM using single tools provided with ArcGIS to analyze elevation data: slope, aspect, hillshaded relief, and a modified hillshade dataset, called "analytical hillshade" that approximates the amount of warmth received by the sun.
- Slope measures the change in elevation measured between a cell and its neighbors. Units can either be in degrees or percent rise.
- Aspect measures the compass direction of a cell's slope. Values range from 0° to 360°, with 0° facing north, 90° facing east, etc. Flat cells are assigned a value of -1.
- Shaded relief or Hillshade calculates the hypothetical illumination of a surface as determined by cell aspect and a light source at a specified angle (elevation) and azimuth (compass direction). Output values range from 0 (receiving no light from the light source) to 255 (a fully illuminated cell).
- Analytical hillshade is a modification of the default hillshade. By setting the sun angle to 30° and azimuth to a southwesterly 225°, we get an estimate of the amount of solar radiation (or warmth) a cell in our DEM dataset might receive.
We will now create a new model in our SierraCostera toolbox to calculate these datasets using our DEM.
- Add a new model to your
SierraCosteratoolbox. Rename it something likeSurfaceToolsand ensure it's stored using relative paths. - Add the Slope tool to your model
- Set it to use the
DEM_90mas the input and calculate slope units inDegrees. - Run the tool and examine the output.
→ Geodesic or planar?
If you examine the help note associated with the choice of using planar or geodesic distances, you'll find that our extent falls a bit in the gray area between the two. You could very well argue that geodesic is the best answer. However, we'll stick with planar in our choices just to be consistent.
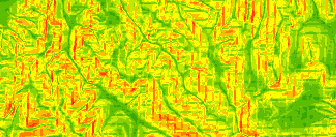
→ Note: It won't happen here, but if you calculate slope and see a boxy pattern in your output as shown below, it's likely an indication that the elevation dataset was resampled (e.g. when re-projecting the data) incorrectly. This occurs when "nearest neighbor" or "majority" resampling techniques are used when a bilinear interpolation should have been used.
- Add the Aspect and two instances of the Hillshade tools to your model.
Set each to use the DEM as the input
For the second Hillshade tool, set the Azimuth to 225° and Altitude to 30° and check Model Shadows. Set the output name to be
insolation.https://www.suncalc.org/#/15.8768,-97.2949,3/2018.09.21/15:17/1/0
Run your model and add the results to your map.
→ Examine each of the resulting raster datasets. Note their values and how they might be best symbolized (color scheme, transparency, resampling type,...) Be sure you understand why some have attribute tables and others do not.
4. Hydrologic analysis
DEM data are also very useful for deriving hydrologic datasets such as stream courses and watershed boundaries. ArcGIS provides a set of tools useful for these analyses (found in the Hydrologic toolbox within the Spatial Analyst tools), but the sequence of tools is important.
To process our DEM data into hydrologic rasters, we\'ll build a new geoprocessing model to hold our sequence of geoprocessing tools. For each of the following steps, be sure you understand what\'s going on and what the resulting cell values are for each derived raster data sets.
4.1 Deriving a stream network from a DEM
Add a new model in the
SierraCosteratoolbox Name it something likeCreateStreamNetworkand set to store relative path names.Add the Fill tool to your model.
- Input =
DEM_90m - Output raster =
FilledDEM(in scratch geodatabase)
The fill tool removes any sinks from the original DEM surface. Sinks, which are simply cells that are lower than all their immediate neighbors, cause havoc when trying to model downstream flow. While some sinks are indeed natural, most are likely artifacts of the DEM creation technique.
- Input =
Add the Flow Direction tool to your model.
- Input =
FilledDEM - Output raster =
FlowD8(in scratch geodatabase) - Flow direction type =
D8 - [Leave Output Drop raster blank]
Be sure your flow direction output only has 8 distinct values (1 ,2, 4, 8, 16, 32, and 128). If not, then you are not using a filled DEM or some other error has occurred.
- Input =
Add the Flow Accumulation tool to your model.
- Input =
FlowDir - Output =
FlowAcc(in scratch geodatabase) - Output data type =
Integer(to speed processing and save disk space)
→ Save your map and run the model. Examine the Flow Accumulation results: do you understand what each cell\'s value represents?
- Input =
Threshold flow accumulation into a stream network using the Set Null tool.
- Input raster =
FlowAcc - False raster or constant value =
1 - Output raster =
StreamGrid(in scratch geodatabase) - Expression =
VALUE < 300
- Input raster =
This procedure sets any cell with fewer than 300 cells draining through it to NoData; the remaining cells are considered stream cells. The choice of 300 is chosen somewhat arbitrarily; Would a higher or lower number produce a map of fewer, larger streams (more cells set to NoData)? Which would label more cells as stream cells. A common practice is to compare the results to an existing stream layer with a known resolution (e.g. 1:24,000 USGS Topo Quads).
Since there are no USGS Topo Quads for Oaxaca, this method won't work. Instead, we can compare our results to INEGI data provided in the map service layer. Add the layer (Located in the LayerTemplates folder), then zoom your map to a scale of 1:50,000. Compare your stream features to those of INEGI when zoomed to this scale. Are they in roughly the same location? Is the level of detail consistent? If so, you can use that to justify your choice of 300 as a cutoff value for flow accumulation to produce a reasonable stream data set
Add the INEGI stream layer to your map and compare your streams to INEGI's.
In the Catalog pane of your project, locate the
Acervo de informacion geografica INEGI (Mapa Digital de Mexico) on gaia.inegi.org.mx.wmsobject. Right click it and select "Add to Project."The entry should now appear in the Servers section in your Catalog pane. Double click it to reveal what data services are available through this connection. Locate and add 'Corrientes de Aqua ' to your map:
Servico WMS>Servico WMS>T50m>Corrientes de Aqua
View your derived streams to those of INEGI. Do you have noticeably more or fewer streams?
Calculate stream order from the Streams raster using the Stream Order tool.
- Input stream raster =
StreamGrid - Input flow direction raster =
FlowDir - Output raster =
StrmOrder(in scratch geodatabase) - Method =
Strahler
- Input stream raster =
Convert stream order raster to a vector stream dataset with the Streams to Feature tool.
- Input =
StrmOrder - Flow direction =
FlowDir - Output =
Streams.shp(in Data Folder) - Un-check
Simplify polylines
The result can be symbolized using graduated symbols on the GRID_CODE attribute, which represents stream order, to create a nifty map of the stream network.
- Input =
We now have a vector stream network dataset completely derived from the DEM. It's not as accurate as a map digitized from aerial photos or recorded by wading through the stream with a GPS, but it's a useful dataset derived solely from DEM data -- and since DEM data are available for nearly all terrestrial regions of the globe, it's a technique we can apply quickly and easily for virtually any location!
4.2 Calculating upstream areas
In this section, we'll continue our hydrologic analysis by looking at the technique used to delineate watersheds upstream of a given point. We'll do this for the four gauge locations provided.
Add a new model in the
SierraCosteratoolbox calledUpstream tools.Determine catchment boundaries for a set of pour points using the Watershed tool.
- Input flow direction =
FlowDir - Input pour point data =
GaugeLocations - Pour point field =
Id - Output =
Watersheds(in Data folder)
- Input flow direction =
Why do some gage sites appear to have no drainage area? Turns out there are two potential issues going on here.
First is the extent of the analysis: by default, the watershed tool's analysis extent is the intersection of inputs, which is likely the pour point shapefile. If your output looks like it's constrained to a box surrounding the pour points, then set the processing extent environment to "union of inputs".
The second issue may be that your pour points don't fall exactly on the stream. You may need to snap the pour point to an area of high flow accumulation using the snap pour point tool, or the method described below.
Snap the gage sites to likely stream courses using the Snap Pour Point tool.
- Input pour point data =
GaugeLocations - Pour point field =
Id - Input accumulation raster =
FlowAcc - Output =
SnappedGages(in Scratch folder) - Snap distance =
250
Inspect a few gage sites and their snapped counterparts. Evaluate how the chosen snap distance performed: should it be increased? Decreased?
- Input pour point data =
Re-calculate watershed boundaries using the snapped gage locations...
- Input flow direction =
FlowDir - Input pour point data =
SnappedGages - Pour point field =
Value - Output =
Watersheds(overwrite existing copy in Data folder)
Do all the points have reasonably sized drainage areas now? Zoom in to Gage #3. Anything peculiar? No need to fix this for this lab, but how might you fix this?
- Input flow direction =
►An alternative method for snapping pour points... The Snap Pour Point tools may not work effectively if you have many pour points of varying distances to streams. If you set the snap distance too low, the pour point may not reach the stream. If you set it to high you may snap to a larger stream branch than intended. The procedure I outline below overcomes some of these errors by snapping the point to the nearest stream feature -- not just the cell with the highest flow accumulation. You may find this technique more useful in some situations.
Add the Copy Features tool to your model.
- Input Features:
GaugeLocations - Output Feature Class:
SnappedPoints.shp(in Scratch folder)
- Input Features:
Snap the gauge locations to the vector stream features (created previously) using the Snap tool.
- Input Features:
SnappedPoints.shp - Snap Environment:
Features =
Streams.shpType =EdgeDistance =1500 meters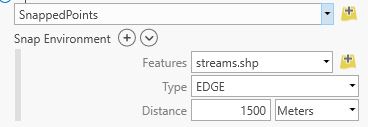
- Input Features:
- Run the tool and view the
SnappedPointsresult. - Create a watershed raster using these snapped points. Don't forget to set the processing extent environment to the union of inputs... This procedure works best when the vector stream network was created with the "simplify polylines" option turned off.
Our hydrologic geoprocessing model now allows us to create some useful datasets, all derived from a single elevation raster. Our streams raster can be used to locate riparian areas, if that's an interest for conservation. And our watersheds dataset could serve as a useful landscape unit for various analyses.
ArcHydro is a 3rd party extension to ArcGIS that allows you do many of these DEM based hydrologic operations and more. You'll see that the NSOE machines may have ArcHydro installed on them as you can see the Arc Hydro Tools in the ArcGIS toolbox: https://www.esri.com/library/fliers/pdfs/archydro.pdf
5. Terrain Analyses
Terrain analyses that go beyond slope, aspect, and hillshaded relief offer additional ecologically relevant information. These analyses point out areas in a landscape where moisture may collect, or where inhabiting plants and animals may be more sheltered from sun, wind, and rain. In this section we will examine and use existing geoprocessing models to compute three useful terrain indices:
- Topographic convergence index (TCI) (also known as Topographic Wetness Index or TWI) calculates the upslope contributing area in relation to slope to identify relatively wet and dry locations across a landscape.
- Topographic Position Index (TPI) examines a cell's elevation relative to its neighbors to identify peaks and valleys within a landscape. It is scale dependent and often is calculated at multiple scales.
- Slope position uses topographic position index to classify a landscape distinct, ecologically relevant classes based on relative levels of exposure.
- Landforms are determined by linking features found at fine scale topographic analysis with those found at more coarse scales. Landforms are another way to classify a landscape into ecologically relevant units.
Each of these analyses is based solely on DEM data. The geoprocessing models used to calculate these are located in the ENV761\_TerrainModels.tbx file, located in your workspace. Many of these tools are based on work done by TNC's Andy Weiss, documented here: http://www.jennessent.com/downloads/tpi-poster-tnc_18x22.pdf
5.1 Topographic Convergence Index (TCI)
Topographic convergence index (TCI) is often used as a proxy for moisture as it reflects the likelihood that water will drain to and remain at a certain location. TCI is calculated as the log of the ratio of drainage area for a given pixel to the tangent of its slope:
...where is drainage area and is the tangent of the slope angle. We have slope, computed in degrees, and flow accumulation from which we can derive drainage area, so we can compute TCI from these. First we'll compute TCI from our D8 flow accumulation:
♦ Topographic Convergence from D8 Flow Accumulation
Create a new model in your toolbox to hold TCI calculations.
Add the Flow Accumulation and Slope (degrees) raster datasets created earlier.
To compute drainage area from flow accumulation, we need to:
- Add a '1' to all values, to include the cell itself.
- Then multiply all values by area of a given cell, 8100 in our case, to get a value in m. (Note, you can also compute the cell size in your model using the
Get Raster Propertiestool.)
Add a raster calculator tool to run these calculations. You should get values from
8100 to 1.5481935e+09.To convert our slope to tan(slope), we need to:
- Convert our slope from degrees to radians (multiply by pi/180).
- Compute the tangent of our slope, now in radians.
Add a raster calculator tool to compute
Tan(<slope in degrees> * math.pi / 180).→ The range of values in the slope raster, in radians, should be
0 to 1.16947.→ The range in values of the tangent of slope (in radians) should be
0 to 2.3565.Alternatively, we could just compute slope in percent and multiply by 100 which equals tan(slope)!
Compute TCI by taking the natural log of the drainage area over tan(slope).
Values should range from
8.47715 to 27.3727Examine your results. You'll likely see areas of NoData occurring where slope = 0 (as is undefined). To fix this we can recode all cells with zero slope with a minimum value, say 0.001 degrees, and then compute tan(slope) and update our values.
The ComputeTCI model in the ENV761_TerrainModels toolbox includes this adjustment. Take a look at this model and run it if you wish. Output TCI values will change to
8.47715 to 34.4018.
♦ Topographic Convergence from DINF Flow Accumulation
We can improve our drainage area from the one created above. That one was created using the 8-direction (D8) flow direction raster, which is still useful for deriving stream layers. However, computing flow accumulation from an infinite direction flow direction raster (DINF) will be far more precise and thus give us a better product. So...
Add a new model or add the following to an existing model in your toolbox for DINF TCI.
Compute a new flow accumulation raster derived from an infinite-direction flow direction raster.
→ Make sure you start with your filled 90m DEM.
Convert your d-inf flow accumulation values from cells to drainage area, in m. As above...
The values for drainage areas should range from
8100 to 1.54805e+09Compute using the drainage area derived from the DINF flow direction.
The range of values should be:
8.67853 to 27.3725Optionally, use the ComputeTCI tool provided to compute TCI with adjustments for zero slope areas.
The range of values should be:
8.67853 to 34.4018
Run the tool and add the outputs to your map. Add an appropriate color ramp and set them to be partially transparent, and then display them with the hillshade map underneath. Be sure you understand what high and low values represent.
5.2 Topographic Position Index (TPI)
The topographic position index (TPI) reveals peaks and valleys within a landscape by comparing each cell's elevation with the mean elevation of neighboring cells. A peak will be higher relative to its neighbors, and valley will be lower. Thus we simply need to subtract a pixel's actual elevation from the mean elevation of its neighbors.
Topographic position is scale dependent; the size of the neighborhood (usually an annulus) chosen will reveal different features. Smaller radii reveal a dendritic network of both main and lateral ridges as well as drainage networks. Larger radii reveal major ridge lines and drainage areas; smaller lateral features disappear.
We will compute both a fine and a coarse TPI.
Add the Topographic Position Index tool to your Terrain Analysis model.
- Input DEM =
DEM_90m - Neighborhood = Annulus with an inner radius of
1cell and an outer radius of5cells - Output =
TPI_fine(data folder)
- Input DEM =
Add another instance of the Topographic Position Index tool to your Terrain Analysis model.
- Input DEM =
DEM_90m - Neighborhood = Annulus with an inner radius of
20cells and an outer radius of25cells - Output =
TPI_coarse(data folder)
- Input DEM =
Run the tools and add the outputs to your display. Like TCI, set the maps to be 40% transparent and display with the hillshade underneath. View the results and play with the inner and outer radii so that the two datasets display different phenomena.
5.3 Slope Position
As described in Weiss poster on landform analysis, we can reclassify the continuous value in the topographic position result into discreet slope position classes representing functional divisions in the landscape. What values to choose to define the ranges within the reclassification depends on the topography of your area: regions with little topographic relief should use narrower ranges while areas of high relief (like ours) can use larger ones.
Weiss proposes, as a standard, repeatable method, using standard deviation units.

Manual calculation of Slope Position from TPI
You can use the Get Raster Properties tool to calculate the standard deviation of a TPI raster, and then use that value to manually define the breaks in a Reclassify tool (or a series of Con statements in a Raster Calculation) to create a Slope Position dataset.
Using the provided Slope Position script tool
Because the above is not terribly sophisticated by does require a lot of typing (and room for mistakes), I've created a simple Python script-based tool that calculates slope position from TPI. The Slope Position (Raster Calc) tool provided simplifies this somewhat, but the script-based tool I provide is more robust. (Raster Calculator tools are notoriously finicky). We'll use this Python-based one...
Add two instances the Slope Position tool (the one in the Scripts folder in your toolbox) to your Terrain Analysis model. (The tool is found in the Scripts folder of the
ENV761_TerrainModelstoolbox.) One instance will be for the fine TPI dataset and the other for the coarse TPI one.Link the Slope position tool with the Slope dataset and with your respective TPI dataset.
Run the model. Add the results to your display. Use the
SlopePosition.lyrxfile in the LayerTemplates folder to symbolize your output. (Though you still may want to set the transparency to 40% and show it on top of the Hillshade map.)→ Alternatively, use the
Apply Symbology from Layertool in your model to apply the symbology.
5.4 Landforms
Combining the coarse and fine scale TPI (with slope further dividing some classes) reveals many unique landforms within our landscape (See the Weiss poster). As in calculating Slope Position, you could do this manually using a series of nested Con statements designed to implement the set of conditions presented in Weiss' poster:

Again, however, it would be both exceedingly tedious and quite error prone to type all this out. So rather than have you do this, I have created another Python script based tool that does this quite easily.
- Add the Calculate Landform tool to your model.
- Set the inputs to be the slope dataset and the two TPI datasets.
- Run the model. Add the results to your display. Use the LandForm.lyrx file in the LayerTemplates folder to symbolize your output.
♦ Summary
In doing this lab, we've generated a number of conservation-relevant datasets, all originating from just a digital elevation model. The techniques used here can be adjusted only slightly (with different inputs and analysis parameters) to add many more useful datasets on which we can base our prioritization decisions.
It is essential that you understand any models that you use, particularly what assumptions are made in using them and how they might affect results. Be sure to study the models in the TerrainModels toolbox noting how they work. Are any assumptions made within these models? What are the impacts of these assumptions? What could we do to validate any assumptions we make?